
A (Markov) Chain Reaction
Using bags of sand to understand the 25.12 meta

How can you tell which decks are “the best decks”?
To some extent, this isn’t the most important question. There is much more to netrunner than simply playing “the best deck”, even for the most competitive players. Tournaments are an endurance contest, and if you want to make it all the way to the end then it seems important that you play a deck that you are both comfortable with and that you enjoy playing. But you will also want to know what your options are, and what challenges you are likely to face. Which is where it can help to understand what is and isn’t doing well in the meta.
We can start by looking at win rate. It’s an easy enough statistic to put together, but it’s lacking in context. Not every win in netrunner is equal. If I return from a tournament with a Runner deck that went undefeated, but a Corp deck that lost every game, does that mean that my Runner was “the best deck” at the event? Maybe, maybe not—it’s really not clear. If I had won some of my Corp games then I would have faced different opponents with different decks, and then maybe I would have lost some of my Runner games. My Runner deck obviously performed really well at the mid-tables, but it’s not clear that it would have performed as well at the top.
To try and accommodate for this, at The Surveyor we focus on decks—technically IDs rather than decks—that made the Top Cut. We use a metric we call “cut conversion” to account for differing player numbers at different tournaments. We assert that any ID with a cut conversion greater than 1x, and a win rate greater than 50%, can be considered a “high performing” ID. From this, we infer what “the best decks” are. We are probably right about 80% of the time1.
This combination of win rate and cut conversion is good enough for tomorrow’s chip wrapper, but it’s still lacking in context. It tells us which decks are (probably) good, but it doesn’t really tell us why.
So, when Lucy shared some meta analysis that she’d done using Markov chains my interest was piqued. And then when she explained to me how Markov chains actually work, I got quite excited.

Who or what is a Markov Chain?
Imagine that you show up at a tournament and everyone is given a bag of sand. You play a game against an opponent, and the winner of that game takes some sand from their opponent’s bag and adds it to their own. This continues until the end of the tournament, where you weigh everyone’s bag to see who has the most sand. So far, so standard tournament scoring system. This is just a very messy way of keeping track of win rate. You may as well play netrunner at the beach.
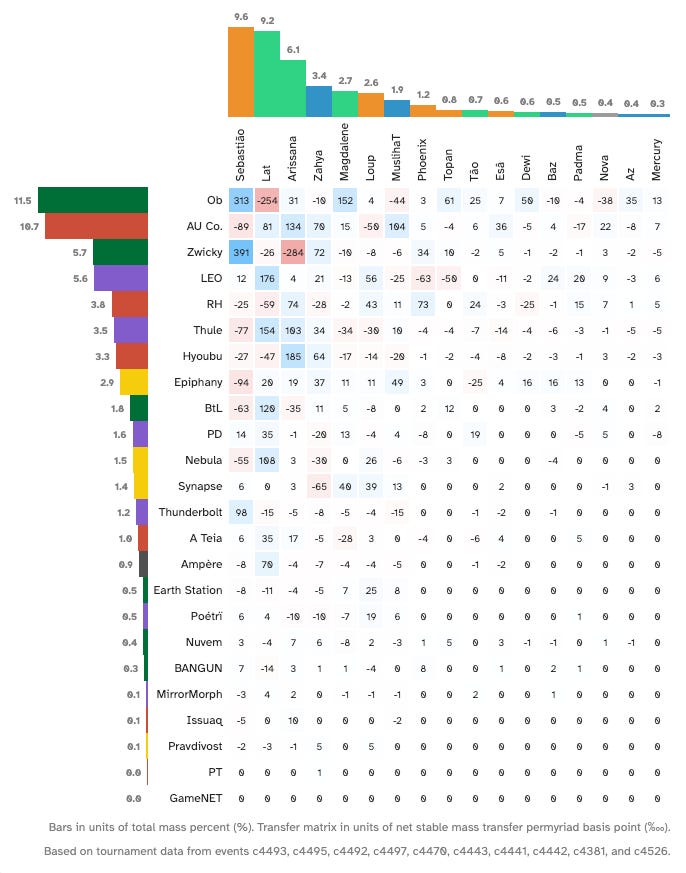
Now imagine that your sand is shared amongst all of the players that are playing the same ID as you, and across all of the tournaments that have been—and will be—played in 25.12. It’s not your sand, it’s team Hoshiko’s sand. When you win as Hoshiko against LEO you are taking sand from the team LEO bag, and adding it to the team Hoshiko bag. The interesting thing here is that we can keep track of where each team is getting their sand from. Team LEO is giving sand to team Hoshiko, but team Hoshiko is losing some of that sand to team AU Co. Lay this transfer of sand out in a matrix, and you get a picture that doesn’t just tell us which IDs are the best, it tells us about matchup spread as well.
Okay, so now we know which IDs are winning the most games, and we know which matchups they are winning and which matchups they aren’t. That’s really good context to have, but is that everything that we need to know? Does it tell us enough to know which decks are most likely to get into the Top Cut, and which decks are most likely to win a tournament?
This is where we get to the real genius of this model. When you win a game, the amount of sand that you take from the opposing team depends on how much sand that team has. The more sand they have, the more sand you take. Win a game against Poetri and you get a teaspoon of sand for your trouble. Win a game against AU Co. or Ob, however, and it’s time to get the big ladle out.
This is huge. When you put all of this together, what you have is a model that not only tells you which IDs are winning games, and not only tells you which games those IDs are winning, but it weights it all by how much you should or should not care. The end product is the cleanest and clearest meta picture that I have seen to date.
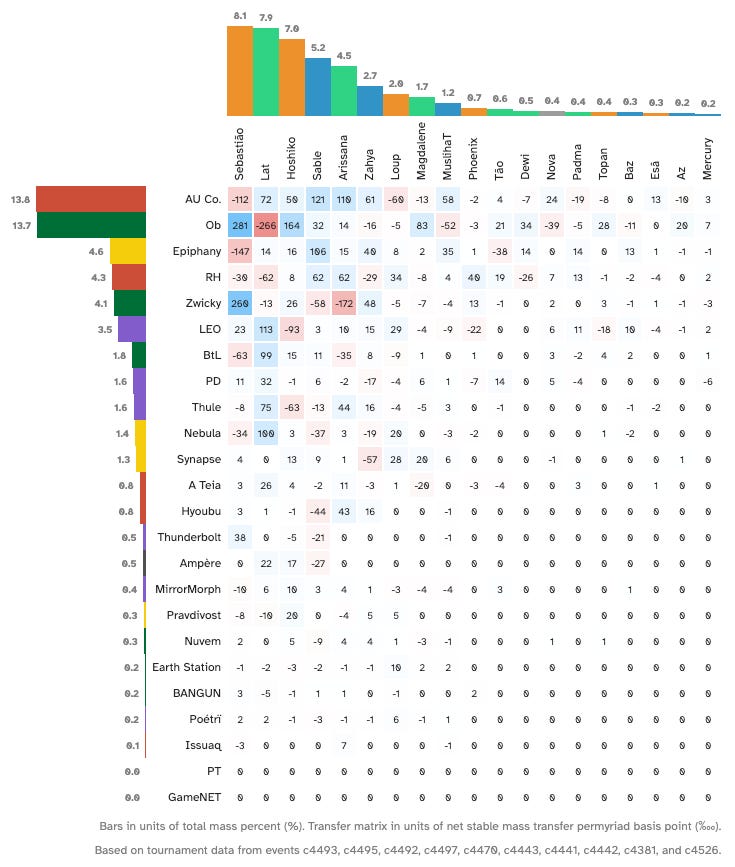
Negative values (in red) indicate a transfer of mass from Corp → Runner.
Positive values (in blue) indicate a transfer of mass from Runner → Corp.
The numbers along the top and down the left hand side indicate how much mass share (as a % of total mass in the system) each ID ended up with, once the system was stable.
All credit for the model goes to Lucy
Who had the biggest sandcastle in 25.12?
Negative values (in red) indicate a transfer of mass from Corp → Runner.
Positive values (in blue) indicate a transfer of mass from Runner → Corp.
For context, the overall Corp win rate in 25.12 was 57% in both Swiss and Top Cuts.
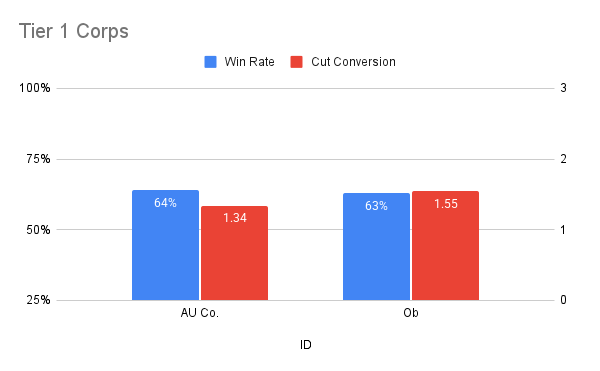
Corp - Tier-1
AU Co. (13.8% of total mass, 64% win rate, 1.34x cut conversion) and Ob (13.7% mass, 63% wr, 1.55 cc) were, without question, the best performing Corp IDs of 25.12—but there was a strong element of rock paper scissors as to which of the two you wanted to play.
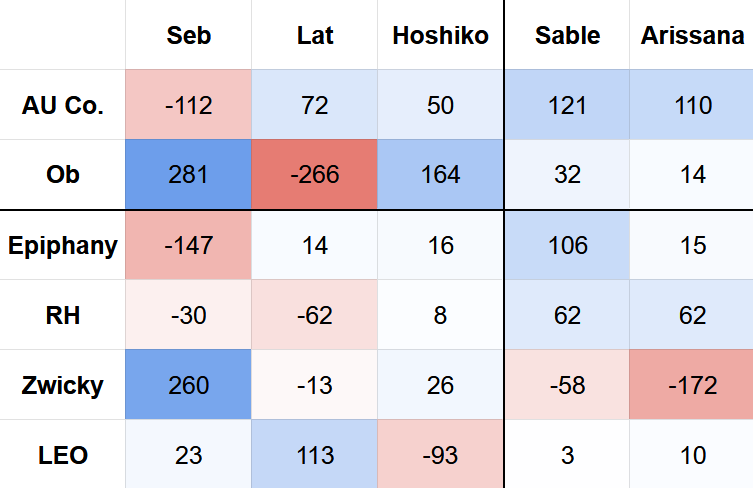
AU Co. took mass from Lat (+72), Hoshiko (+164), Sable (+121) and Arissana (+110), but lost a significant chunk of mass to Seb (-112).
Ob took mass from Seb (+281) and Hoshiko (+164), but lost an even more significant amount to Lat (-266).
So, if you were expecting to face off against Seb you would have been best to play Ob. But if you were expecting to face off against Lat, then you would have been best to play AU Co. If you didn’t know what to expect, then, honestly, it didn’t matter which you played. Both Ob and AU Co. were exceptionally strong in 25.12.
Runner - Tier-1
Seb (8.1%), Lat (7.9%) and Hoshiko (7.0%) came out on top in 25.12.
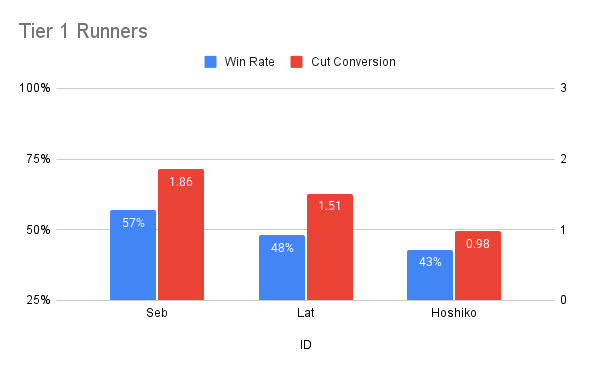
Seb (8.1% mass, 57% wr, 1.86x cc) won mass from AU Co. (-112) and Epiphany (-147) but lost a significant amount of mass to Ob (+281). Seb had the highest win rate and cut conversion overall, and so there is a decent argument that Seb was the best overall runner in 25.12—as long as you were prepared to stomach some highly polarised matchups.
Lat (7.9% mass, 48% wr, 1.51x cc) was a little more balanced. The ethical freelancer won a lot of mass from Ob (-266) and a small amount from RH (-62), but lost some of that mass to AU Co. (+72) and LEO (+113).
Hoshiko (7.0% mass, 43% wr, 0.98 cc) had the weakest win rate and cut conversion of the three, but the most balanced matchup spread overall. She was mostly buoyed by good results against LEO (-93), but held back by poor results against Ob (+164).
This is the reverse side of the Rock-Paper-Scissors contest. If you were expecting lots of AU Co. at a tournament in 25.12 then Seb was your best pick, but if you expected to play against Ob then Lat was a much more sensible choice. If you didn’t expect much of either then you could happily play Hoshiko and clean sweep all of the LEO opponents that you match into.
Corp - Tier-2
Tier-2 Corp options for 25.12 were Epiphany (4.6%), RH (4.3%), Zwicky (4.1%) and LEO (3.5%).
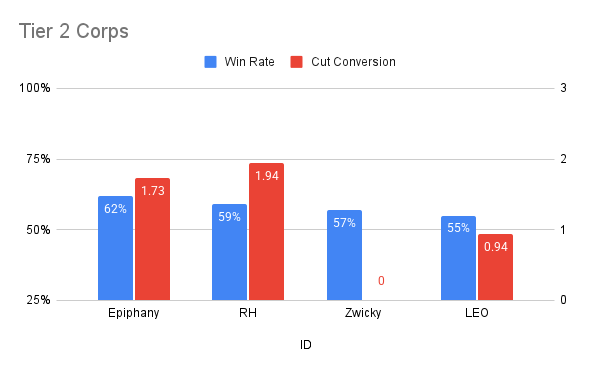
Despite an impressive win rate and cut conversion, Epiphany (4.6% mass, 62% wr, 1.73x cc) was not able to win those games that mattered most. The yellow asset spam ID won significant mass from Sable (+106), but lost even more to Seb (-147).
RH (4.3% mass, 59% wr, 1.94x cc) was much more balanced, but was still winning mass from Tier-2 Runners: Sable (+62) and Arissana (+62), while losing it Tier-1 Runners: Lat (-62) and Seb (-30).
You might be surprised to see Zwicky (4.1% mass, 57% wr, 0x cc) in this Tier-2 list, given that it didn’t make any of the Top Cuts, but Zwicky seemed to have a pretty decent matchup against all of the tier-1 runners. If only it had been able to win more games against Sable and Arissana, then we may have actually seen some of the unsubstantiated ID at the top tables.
LEO (3.5% mass, 55% wr, 0.94 x cc) also had a good showing against Seb (+23) and Lat (+113), but was kept in Tier-2 by the vast amount of Hoshiko (-93) that it had to face, and struggled to beat.
Runner - Tier 2
Sable (5.2%) and Arissana (4.5%) fell into the tier-2 bracket on the runner side.
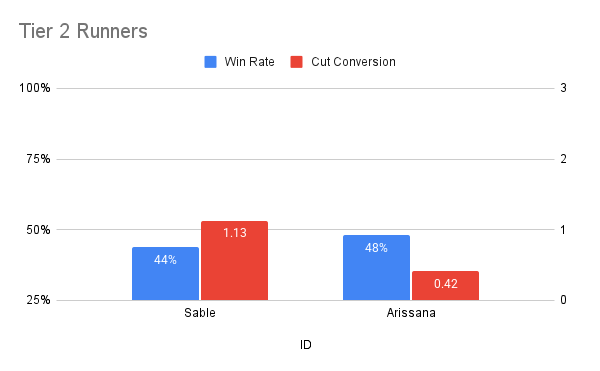
Sable (5.2% mass, 44% wr, 1.13x cc) had a decent cut conversion but a poor win rate. She lost a lot of mass to AU Co. (+121) and Epiphany (+196), and wasn’t really able to pick much up from anywhere else.
Arissana (4.5% mass, 48% wr, 0.42x cc) wasn’t played as much as Sable, but she also lost a lot of mass to AU Co. (+110) whilst also losing a very small amount to Ob (+14).
What does all this mean for Vantage Point?
Given the significant change in card pool it is, of course, impossible to say with any confidence at all what the Vantage Point meta will look like, but let’s speculate anyway.
While we can expect some players to stick to what they know for Districts—particularly AU Co. and Ob on the Corp side—the amount of exciting new cardboard, and an updated banlist means that all bets are off for what 2026 looks like in the long term. Yes, AU Co. and Ob will still be good, no doubt, but it really isn’t clear that they will still so obviously be “the best” Corps by the time that Continentals season rolls around—particularly with the amount of support that other Corp strategies have received in Vantage Point so far.
25.12 Markov chain analysis sans Hoshiko and Sable
To illustrate this point, I asked Lucy what would happen if we removed Hoshiko and Sable from the 25.12 Markov chain model2. In this model, what we see is that AU Co. and Ob are still the best decks, but their final share of mass drops from ~14% to ~11%. AU. Co continues to lose mass to Seb, while gaining mass from Lat and Arissana (and Zahya). Ob becomes super polarised in terms of gaining significant mass from Seb only to lose most of it to Lat.
Zwicky and LEO both gain from the removal of Hoshiko and Sable, going up from ~4% to ~6% final mass share. This bodes well for both of these IDs going into the 26.03 banlist, particularly for LEO which will further benefit from the release of Méliès City Luxury Line and Let Them Dream, even while losing Luminal Transubstantiation. RH mass share doesn’t really move, while Epiphany drops from ~4% to ~3%.
As for the Runner, removing Hoshiko and Sable from the model means that Seb and Lat increase their mass share from ~8% to ~9%, while Arissana increases from 4.5% to 6%.
Whether or not the Deep Dive un-ban further increases the prospects of Shaper remains unclear. AU Co. continues to be the biggest predator of Shaper, and it is not obvious that Deep Dive particularly helps that matchup. But it’s a powerful card, and maybe it gives Shapers enough leeway in their other matchups that they can afford to slot tech cards—such as Airblades—specifically for AU Co..
Regarding Hoshiko, you could make the case that whatever Hoshiko deck you were playing in 25.12 you would have been better off playing in Loup. Theoretically, you would gain equity against AU Co. and Ob—the two most relevant matchups—as well as Epiphany. You would lose some equity against LEO, but Hoshiko was so far ahead in that matchup that it seems to me like a reasonable price to pay. None of the data actually supports this, and, of course, everything will change in Vantage Point in any case, but I think there is good reason to be optimistic about Loup’s prospects as a “reg” Anarch.
Closing Thoughts
Ob and AU Co. were far and away the best IDs of 25.12, and Corp win rates were uncomfortably high. Which runner to play was a rock-paper-scissors choice between Lat and Seb—depending on which Corp you matched into—with Hoshiko being generally okay-ish.
From what we know about Vantage Point so far, it seems likely that AU Co. and Ob will continue to be very strong, but we can probably expect other Corp IDs to join them as tier-1, or, at least, for the gap between tier-1 and tier-2 Corp decks to narrow.
Given the polarised matchups, it’s not obvious that Seb can survive a more diverse Corp meta—to say nothing of the multitude of new cards that Corps will be able to use to defend against Transfer of Wealth. As a more generic and versatile runner, though, we could see Lat continue to flourish, or, if the Corp meta does not diversify beyond Ob and AU Co. then that could prove to be rich soil for any Hoshiko players that move to Loup, although it’s not obvious how well Loup will be able to contend with LEO’s new agenda suite.
Beyond this, while Corps may choose to keep doing what they were doing in 25.12, it looks like Runners are going to have to consider all of the new tools at their disposal and get creative with how to approach this new meta.
Thanks again to Lucy for all the work she did in putting this model together, and to Spiderbro for adding the model to the The Makers Eye.
Go and play netrunner
Excited for the Vantage Point release? Why not take the day off work and come hang out with EA Sports in Norwich for an all day Vantage Point launch party?
Too far to travel? Can’t get the day off work? There are also launch events happening in Torino, Bath, Clovis (CA), Helsinki, Reading, Pittsburgh (PA), Esslingen, Milwaukee (WI), Vancouver, London, Victoria, and Toronto—or why not host your own VP launch party!
What could be more fun than exploring the new cardpool with your friends.
And when you are done with that, why not write about your explorations?
The Surveyor is looking for contributors! If you are interested in writing up a tournament report, or have an idea for an opinion piece about netrunner, you can message me on discord—kikai.noraneko.
Monte Carlo simulation suggests that, when it comes to determining “the best deck”, win rate is 68% accurate and cut conversion is 59% accurate. In this simulation, there was an 18% chance that a “worse deck” had a better win rate and cut conversion than a “better deck”. All credit to theo for this analysis.
There are so many reasons why arbitrarily removing IDs from the model is not a reliable method for analysis, but it is at least interesting.
Huh, if you told me that Sable was losing into Au Co I would've been very confused. I firmly believe that matchup is 5/5 or better for Sable.
I feel like saying that Epiphany was "not able to win those games that mattered most" has to have a huge asterisk, as it did in fact win Worlds!